

WSO2 Machine Learner (ML) provides a user friendly wizard like interface, which guides users through a set of steps to find and configure machine learning algorithms. The outcome of this process is a model that can be deployed in multiple WSO2 products, such as WSO2 Enterprise Service Bus (ESB), WSO2 Complex Event Processor (CEP), WSO2 Data Analytics Server (DAS) etc.
WSO2 ML 1.1.0 (new release) have the anomaly detection feature as well. It is implemented based on the K means clustering algorithm which is discussed on my previous article. In this article I will discuss the steps of building an anomaly detection model using WSO2 Machine Learner.
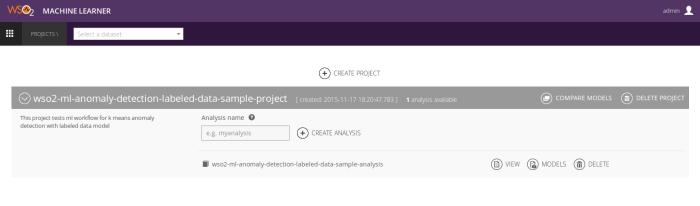
Step 1 – Create an analysis
For every model you have to first upload a dataset and create a new project. Then start a new analysis to build an anomaly detection model.
Step 2 – Algorithm selection
In the ‘Algorithm’ selection process there is a new category called ‘Anomaly Detection’. Under that category there are two algorithms. If your dataset is a labeled one you can select k-means with labeled data. Otherwise you can select k-means with unlabeled data. There are a few model configurations that you have to input in this step.
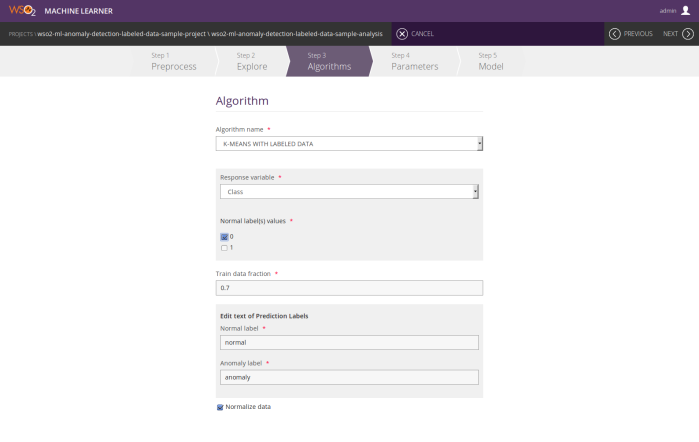
k-means anomaly detection with labeled data
- Response variable
- Normal label(s) values
- Train data fraction
- Prediction labels
- Normalization option
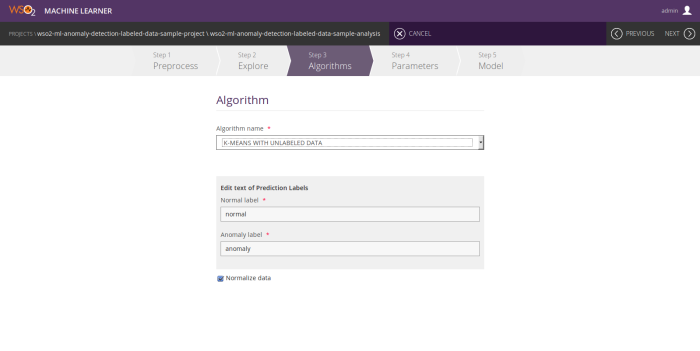
k-means anomaly detection with unlabeled data
- Prediction labels
- Normalization option
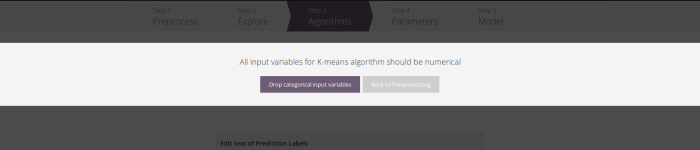
If any categorical features other than the response variable exists in the dataset you will be asked to drop them when you proceed to the next step.
Step 3 – Hyper parameters
In the parameter selection step you have to input necessary hyper parameters for the model:
- Maximum iterations
- Number of normal clusters (since this anomaly detection algorithm is implemented based on k-means clustering you have to input the number of normal clusters that should be built in the model)
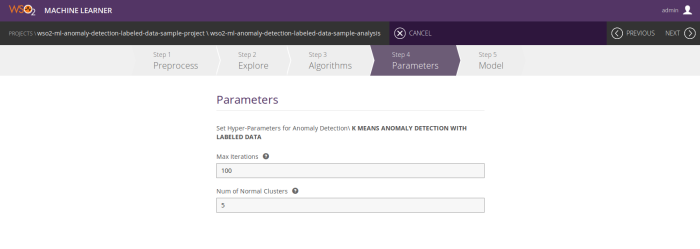
Step 4 – Model building
Then after selecting the dataset version you can build the model.
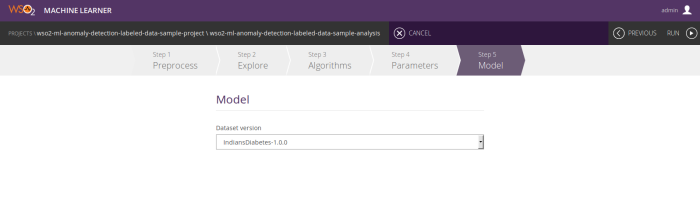
Step 5 – Model summary
After successfully building the model you can view the model summary if you have built the model using k means with labeled data algorithm. The summary gives you an overall idea about the model. It will have useful information about the model such as its F1 score and some other important accuracy measures, confusion matrixes, cluster diagram, etc. So based on this information you will be able pick the best model.
The model is evaluated for the range of percentile values, i.e. for the range of cluster boundaries, to pick the best one. In the model summary, by default, you will see the measures with respect to best percentile value. You can see how the measures change according to the percentile by moving the percentile slider. Based on that you can form an idea about the best percentile value to use for your predictions.
By default we use the percentile range 80-100, but if you need a different range to evaluate the model you can change the range by entering minPercentile and maxPercentile as system properties when you start the server. Keep in mind that you need to input values between 0-100 as percentiles. You can input system properties when you start the server as shown below:
./wso2server.sh -DminPercentile=60 -DmaxPercentile=90
Step 6 – Prediction
This is where you can predict new data using the model. You need to input feature values of a new data point or you can give new data as a batch using a csv or tsv file. You should also input the percentile value to identify the cluster boundaries. The default value will already be there. You can keep it if you aren’t sure about it. If you had labeled data when building the model it will set the optimum value obtained from the model evaluation as the default value. After entering those values you will get the predictions for new data.
If you want to know more about WSO2 Machine Learner you can follow the documentation. You can download the product and try this out with your dataset and it is absolutely free!!!
Also you if you have more interesting ideas you can contribute to the product as well. You can find the source code of WSO2 ML from following repositories. wso2/carbon-ml, wso2/product-ml.




